Hadoop © pepsi-wyl
Hadoop简介
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供了系统底层细节透明的分布式基础架构。Hadoop是基于Java语言开发的,具有很好的跨平台特性,并且可以部署在廉价的计算机集群中。Hadoop的核心是分布式文件系统(Hadoop Distributed File System,HDFS)和MapReduce。Apache Hadoop版本分为三代,分别是Hadoop 1.0、Hadoop 2.0和Hadoop3.0。除了免费开源的Apache Hadoop以外,还有一些商业公司推出Hadoop的发行版。2008年,Cloudera成为第一个Hadoop商业化公司,并在2009年推出第一个Hadoop发行版。此后,很多大公司也加入了做Hadoop产品化的行列,比如MapR、Hortonworks、星环等。2018年10月,Cloudera和Hortonworks宣布合并。一般而言,商业化公司推出的Hadoop发行版也是以Apache Hadoop为基础,但是前者比后者具有更好的易用性、更多的功能以及更高的性能。
单机安装
预先配置
关闭防火墙
1 | # 关闭 |
修改主机名称和添加映射
1 | # 修改主机名称 |
创建Hadoop用户
1 | # 创建用户并使用 /bin/bash 作为shell |
设置SSH免密登陆
1 | # 连续敲击3次回车 |
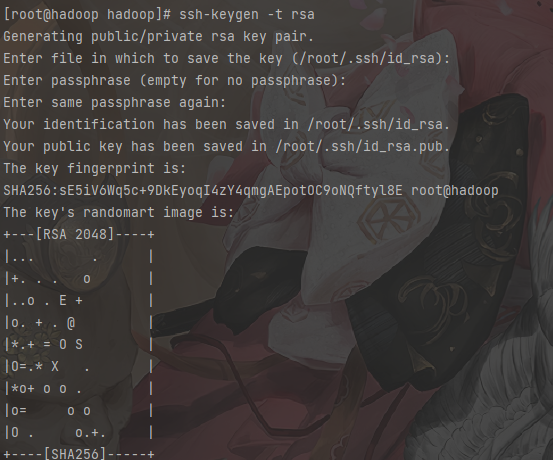
1 | # 查看生成的秘钥对 |

1 | # 追加公钥,执行命令后,根据提示输入 yes 再次回车 |
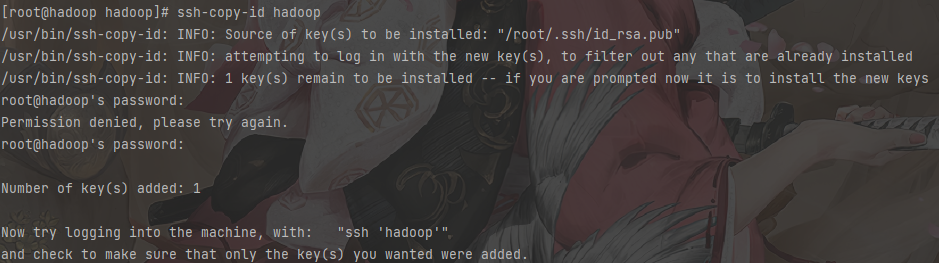
1 | # 查看生成的认证文件 authorized_keys |
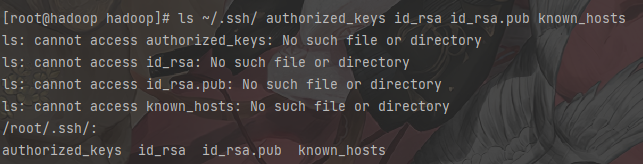
1 | # 验证免密 |

安装JAVA并配置环境变量
1 | 上传至服务器并且解压更改名称 |
1 | 编辑配置文件 |
1 | 检查是否安装成功 |

安装Hadoop并配置环境变量
1 | 上传至服务器并且解压更改名称 |
1 | 查看是否可用 |

1 | 编辑profile文件 |
1 | hadoop version |

单机非分布式运行
主要用来调试时使用
1 | 进入hadoop的安装路径 |
伪分布式运行
创建hadoop存放数据的目录
1 | # 切换路径 hadoop的安装路径 |
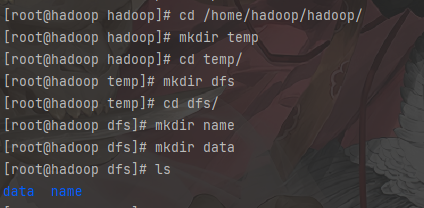
修改配置文件
1 | hadoop 配置文件都在hadoop 安装目录下的 /etc/hadoop 中 |
1 | vim hadoop-env.sh |

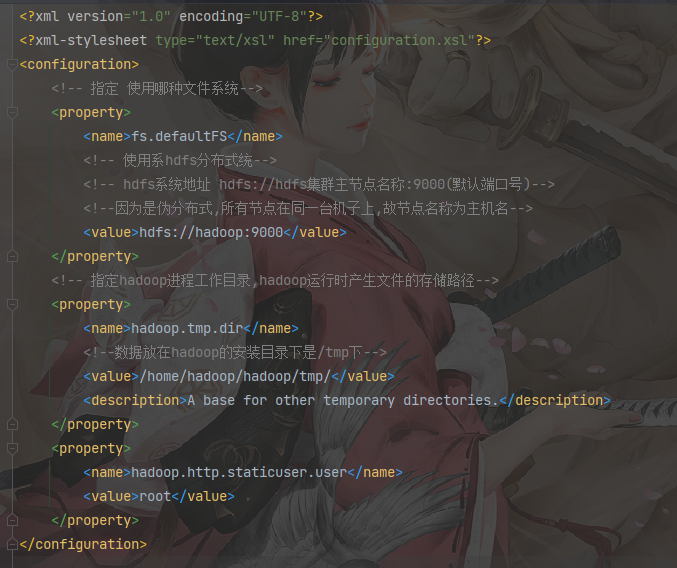
1 | vim core-site.xml |
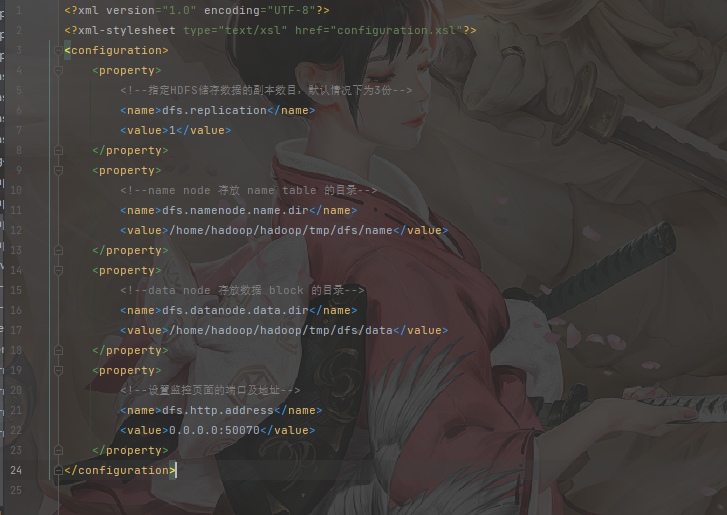
1 | vim hdfs-site.xml |
1 | vim mapred-site.xml |
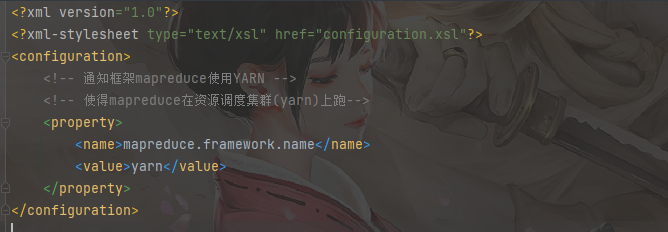
1 | vim yarn-site.xml |
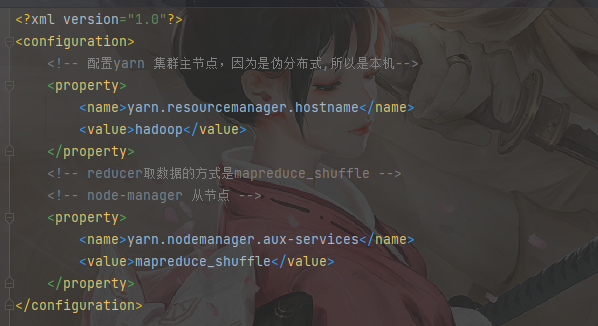
修改环境变量
1 | 编辑配置文件 |
格式化集群文件系统
1 | hadoop namenode -format |
启动伪分布式
1 | start-all.sh |
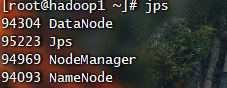
1 | jps |
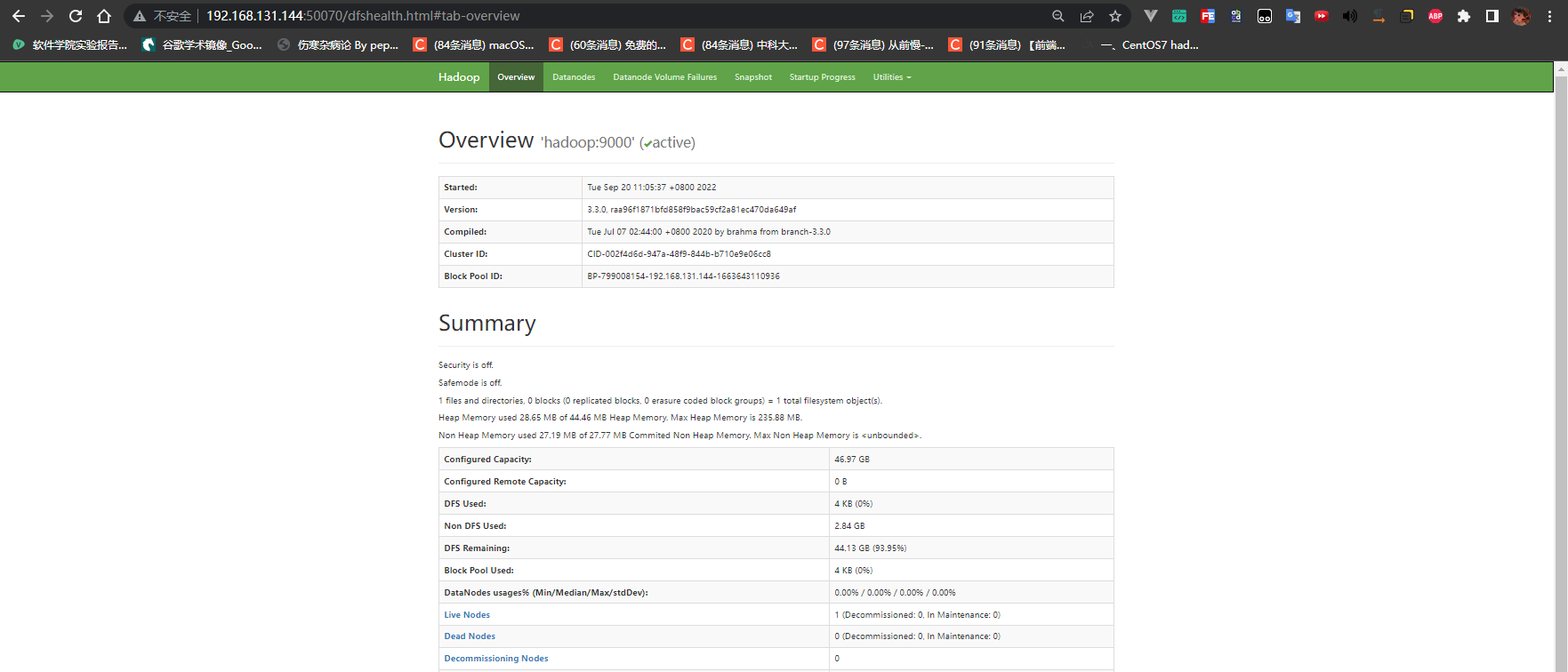
Web管理界面(关闭防火墙或者放行端口)
1 | http://192.168.131.144:50070/ |
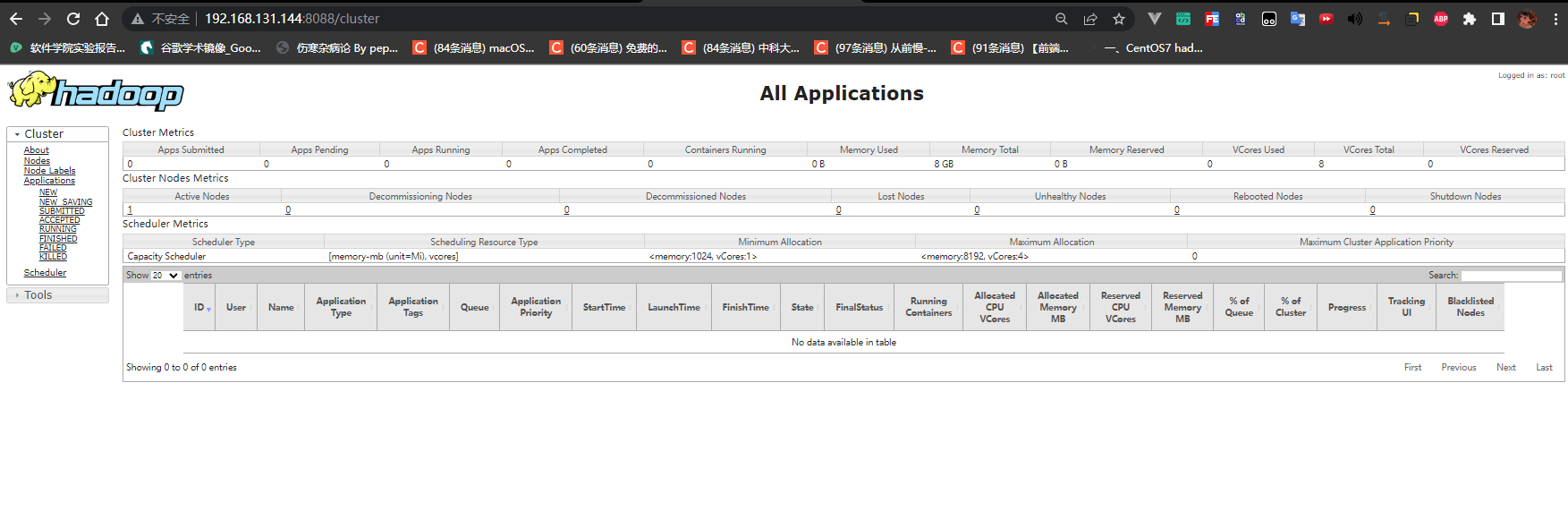
1 | http://192.168.131.144:8088 |
关闭伪分布式
1 | stop-all.sh |
分布式安装(选作)
虚机分配
| hadoop1:192.168.131.145 | hadoop2:192.168.131.146 | hadoop3:192.168.131.147 | |
|---|---|---|---|
| HDFS | NameNode DataNode |
DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager |
NodeManager |
克隆3台虚拟机修改静态IP进行操作
准备工作
关闭防火墙(3台)
1 | 关闭 |
修改主机名称和修改映射(3台)
1 | 修改主机名称 |
1 | 修改主机名称 |
1 | 修改主机名称 |
设置SSH免密登陆(3台)
1 | 3次回车 |
1 | 3台主机的全部公钥私钥在3台机器上全部存储(粗暴复制) |
安装JDK并配置环境变量(3台)
1 | 上传至服务器并且解压更改名称 |
1 | 编辑配置文件 |
1 | 检查是否安装成功 |
安装Hadoop并配置环境变量(3台)
1 | 上传至服务器并且解压更改名称 |
1 | 查看是否可用 |
1 | 编辑profile文件 |
1 | hadoop version |
修改环境变量(3台)
1 | 编辑配置文件 |
修改配置文件(3台)
1 | hadoop 配置文件都在hadoop 安装目录下的 /etc/hadoop 中 |
1 | vim hadoop-env.sh |
1 | vim core-site.xml |
1 | vim hdfs-site.xml |
1 | vim yarn-site.xml |
1 | vim mapred-site.xml |
1 | vim workers |
格式化集群文件系统(3台)
1 | hdfs namenode -format |
启动分布式集群(3台)
1 | start-all.sh |
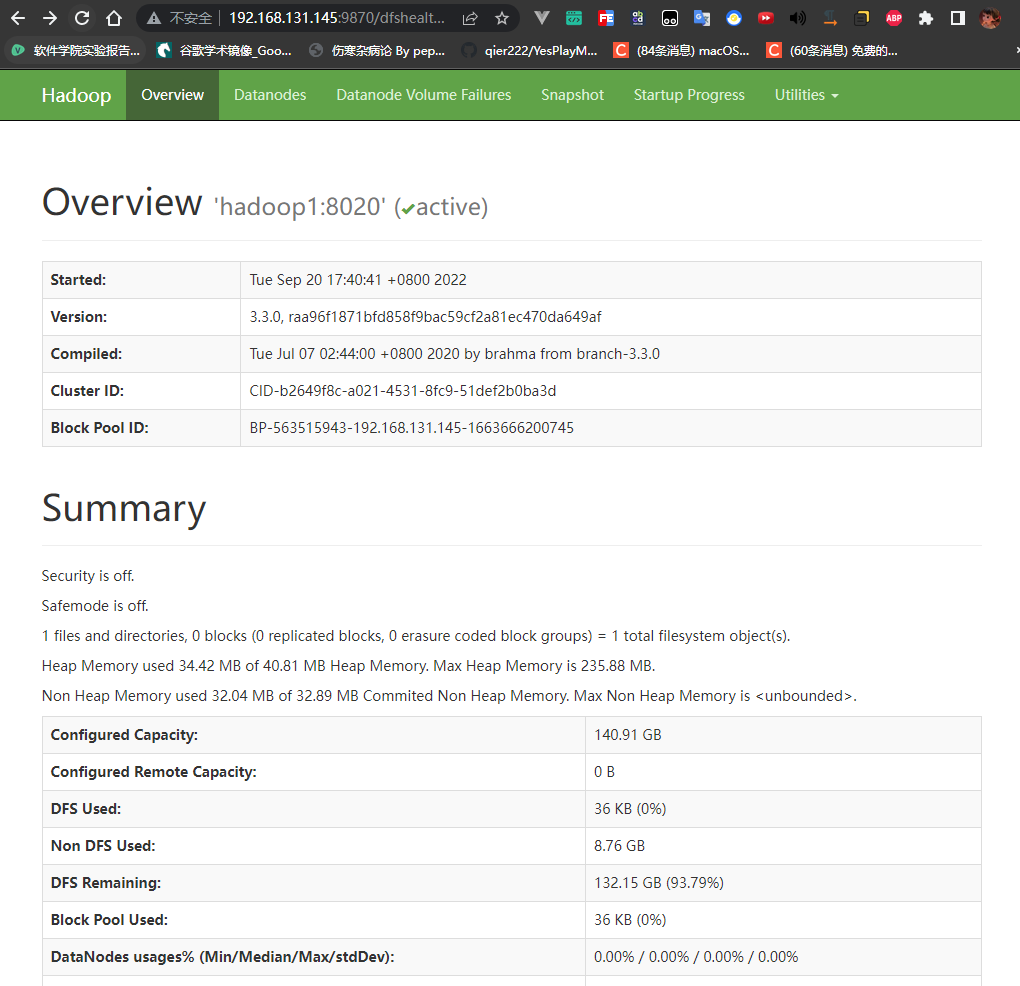
Web管理界面(关闭防火墙或者放行端口)
1 | hadoop1的IP NameNode |
1 | hadoop2的IP ResourceManager |
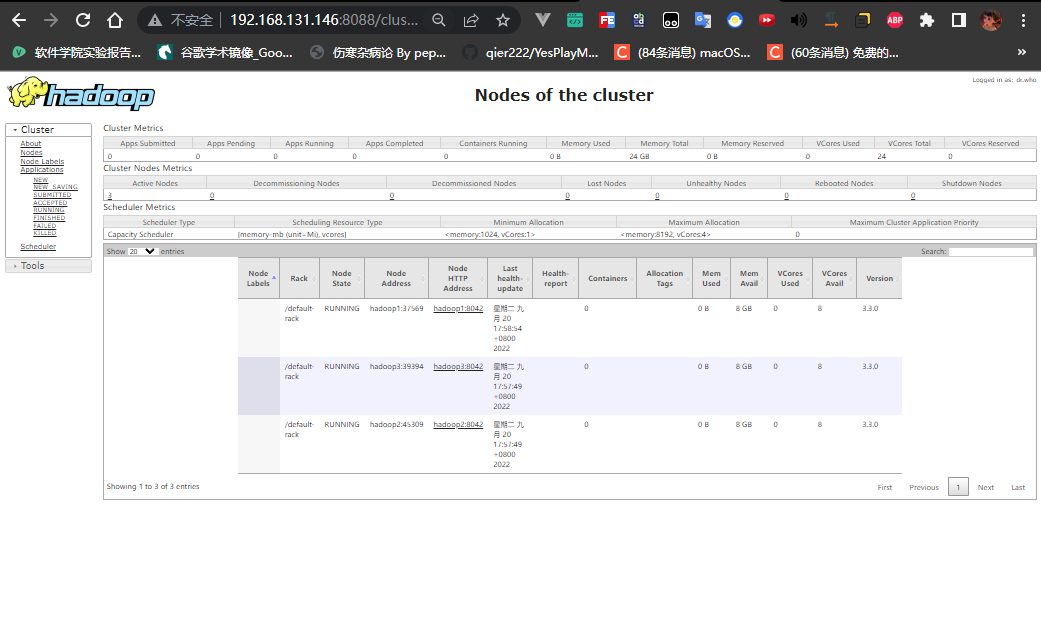
关闭分布式集群(3台)
1 | stop-all.sh |
文件的操作综合应用
命令行操作
1 | # 列出HDFS文件 |

1 | # 在HDFS中创建文件夹 |

1 | # 删除HDFS中的文件或文件夹 |

1 | # 上传文件到HDFS |


1 | # 查看HDFS下的某个文件 |

1 | # 将HDFS中的文件复制到本地系统中 |

1 | # 修改HDFS中的文件和文件夹的名称 |

HDFS API编程
代码链接 https://github.com/pepsi-wyl/HDFS_API
BUG 解决java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset
1 | <dependencies> |
1 | public class HDFSUtils { |
1 | // 列出HDFS文件 |
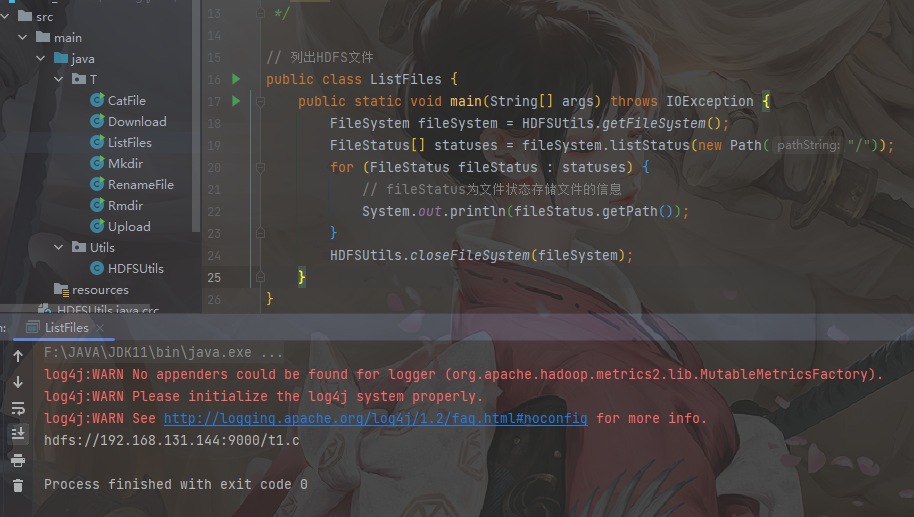
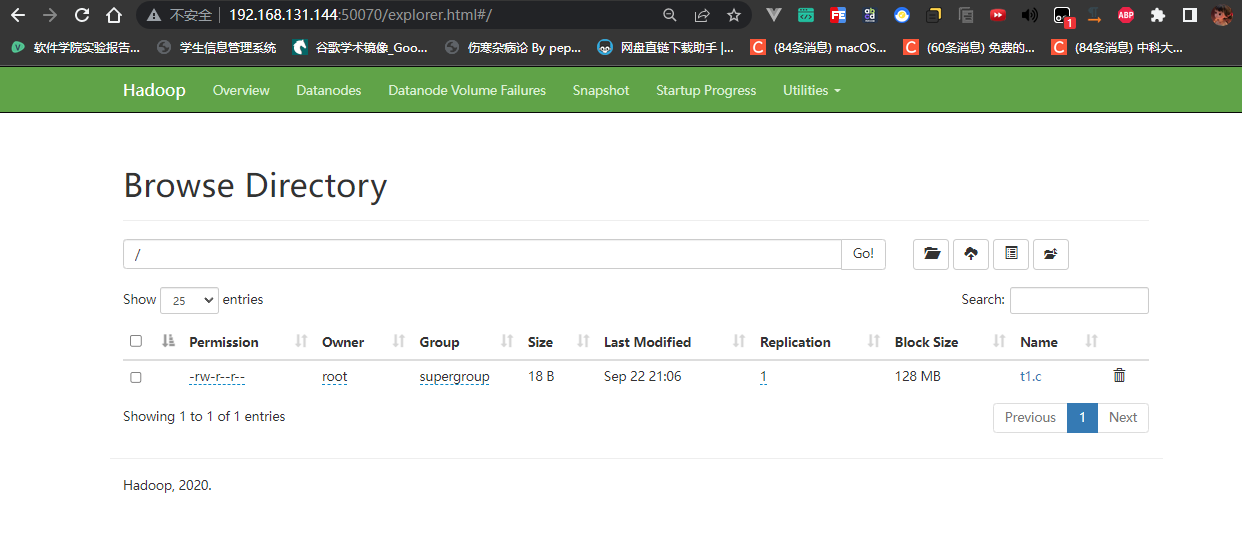
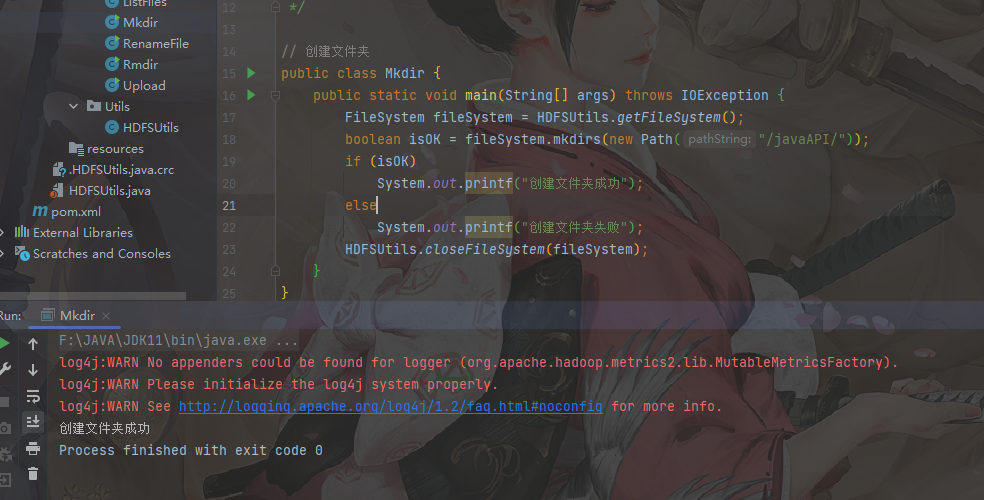
1 | // 创建文件夹 |
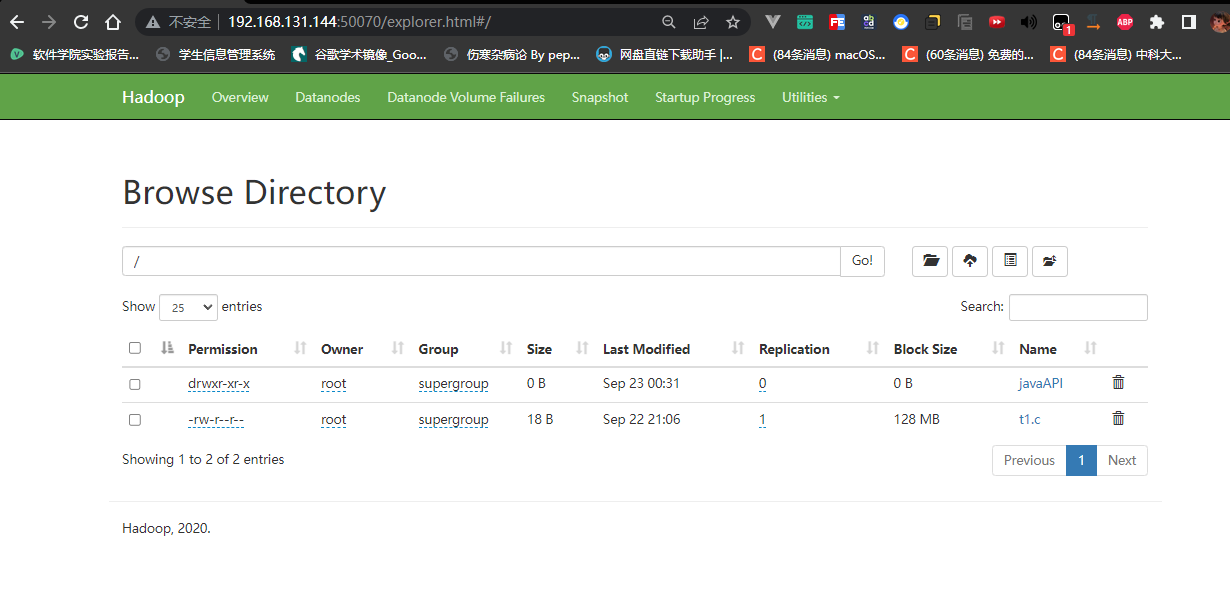
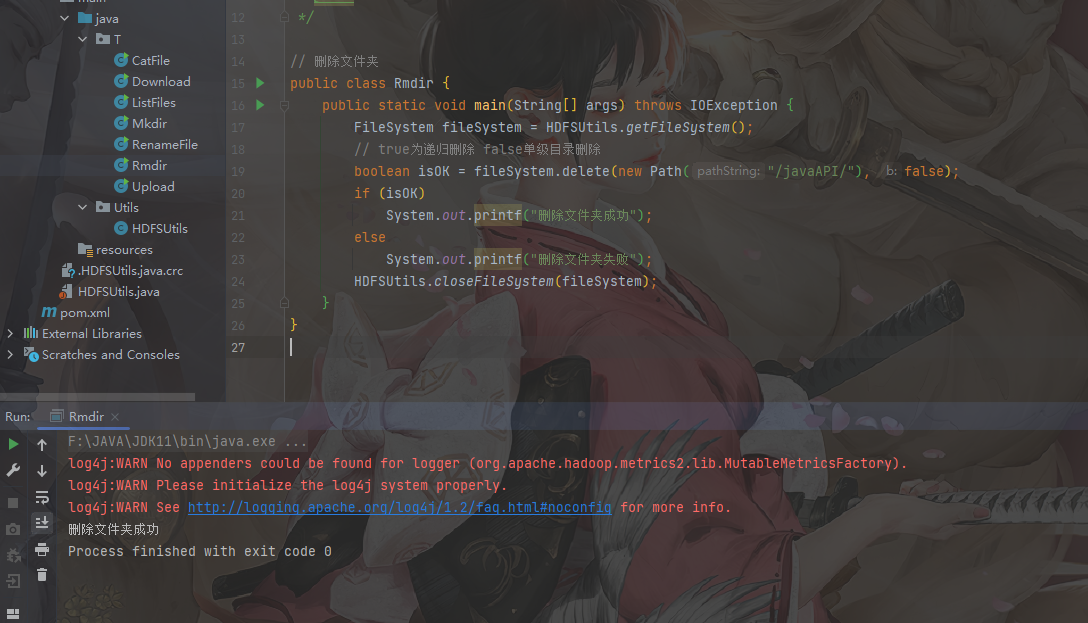
1 | // 删除文件夹 |
1 | // 上传文件 |
1 | // 下载文件 |
1 | // 修改HDFS中的文件和文件夹的名称 |
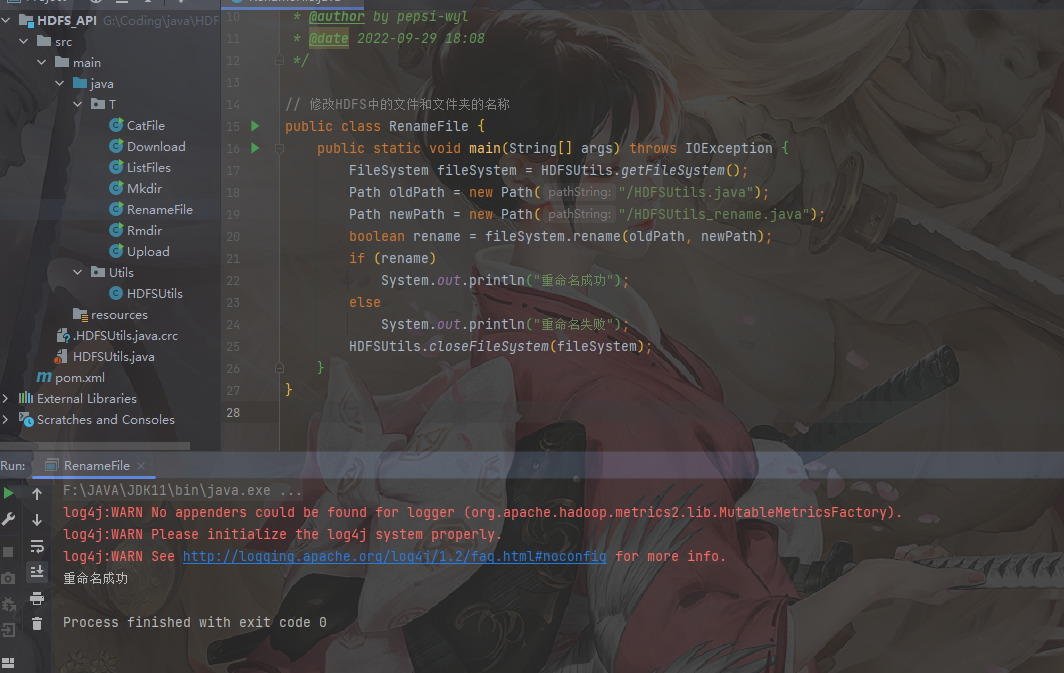
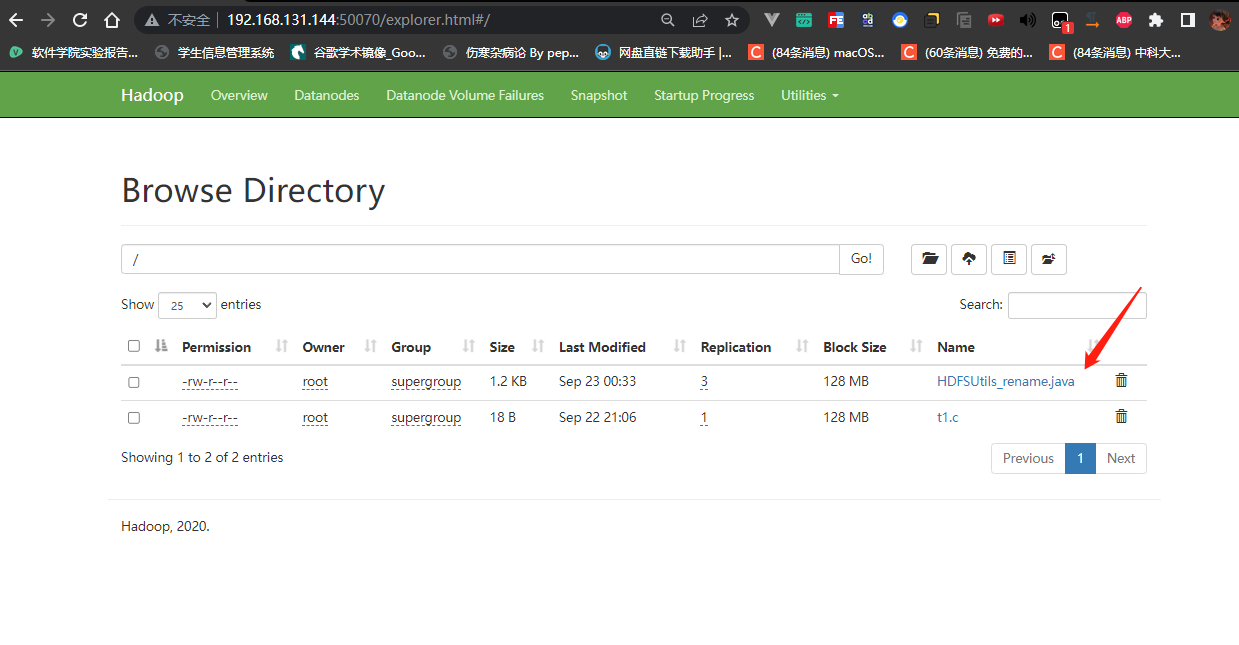
1 | // 查看HDFS中的文件 |
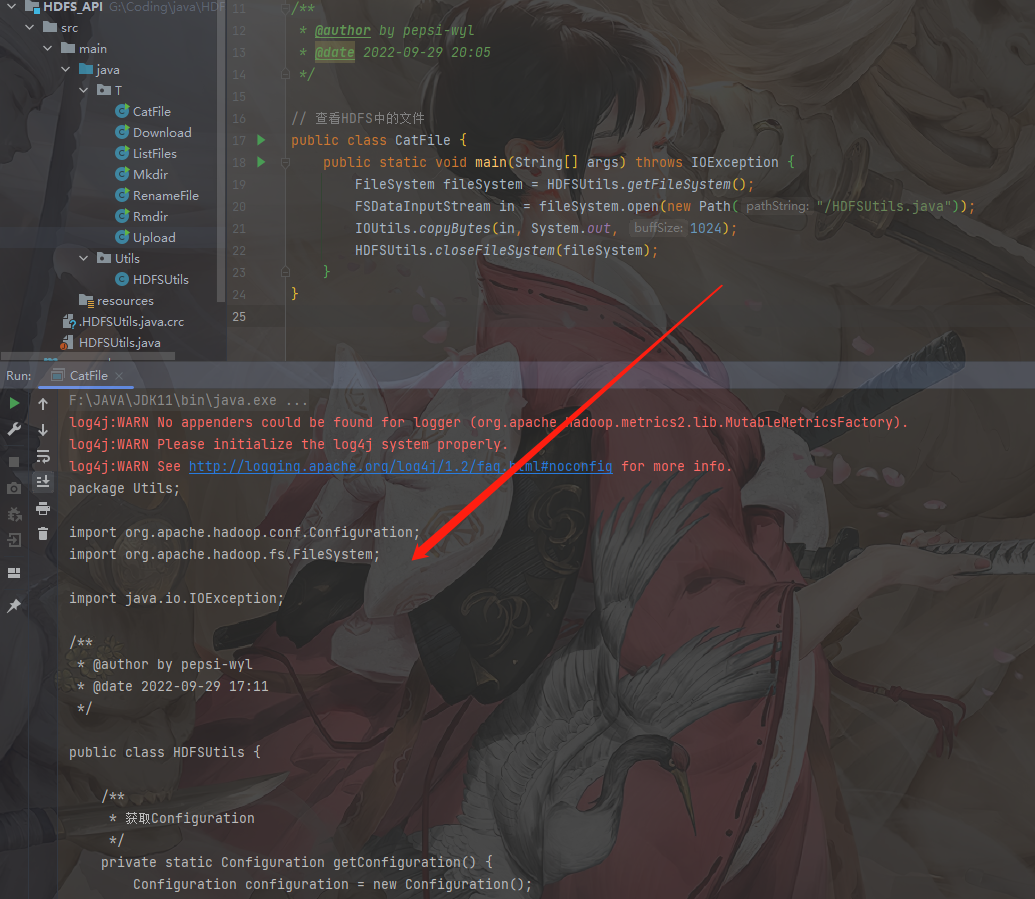
MapReduce基础编程
使用命令行编译打包词频统计程序
HDFS中创建文件
1 | wordfile1.txt |
上传到HDFS中
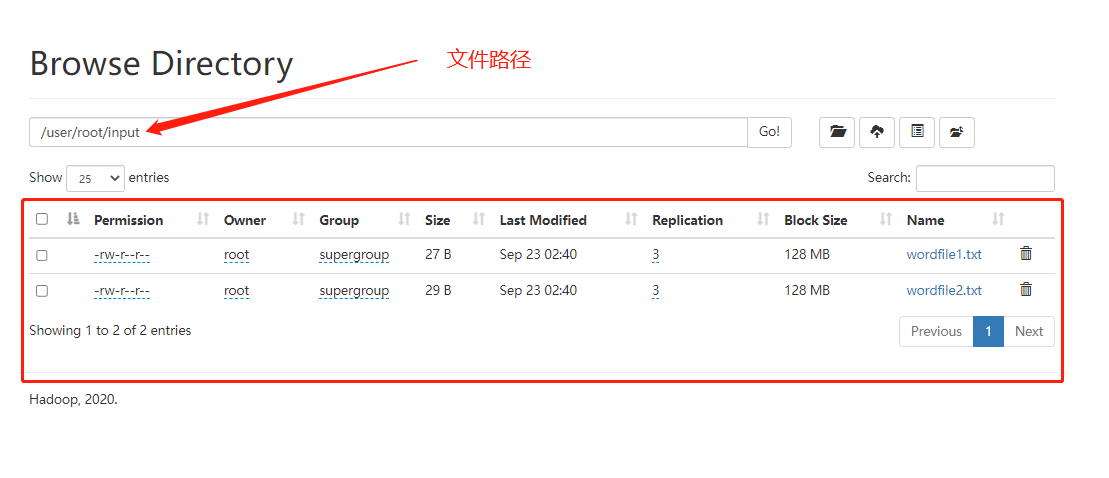
编写源文件
1 | # 源文件编写在hadoop的安装路径下 |
1 | import java.io.IOException; |
编译打包运行
1 | # 在hadoop的安装路径下操作 |
编译

打包

运行
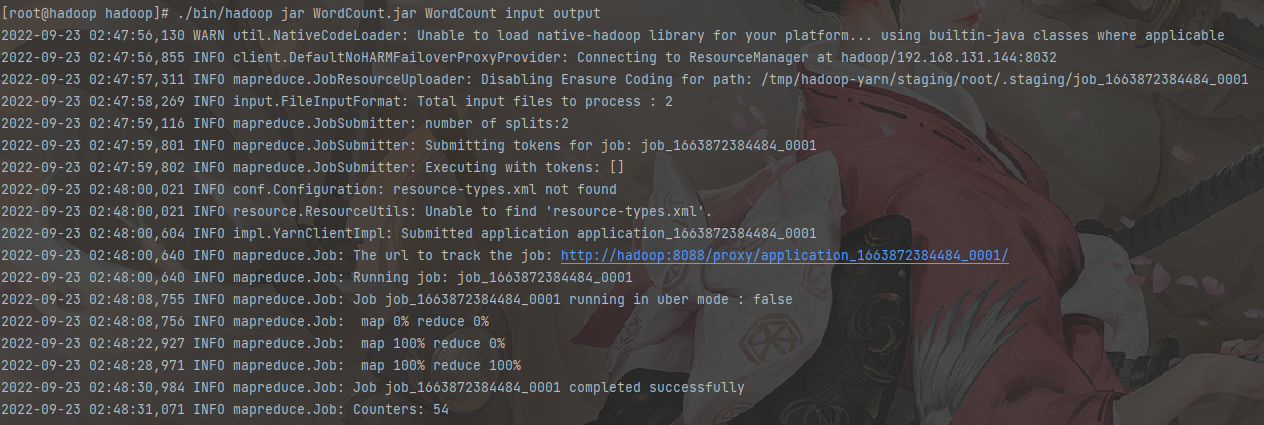
查看结果

排错
Hadoop:找不到或无法加载主类org.apache.hadoop.mapreduce.v2.app.MRAppMaster
https://blog.csdn.net/lianghecai52171314/article/details/103231176
使用Idea编译运行词频统计程序
HDFS中创建文件
1 | wordfile1.txt |
上传到HDFS中
maven工程
创建工程
导入依赖
1 | <dependencies> |
编写源码
1 | import org.apache.hadoop.conf.Configuration; |
打包
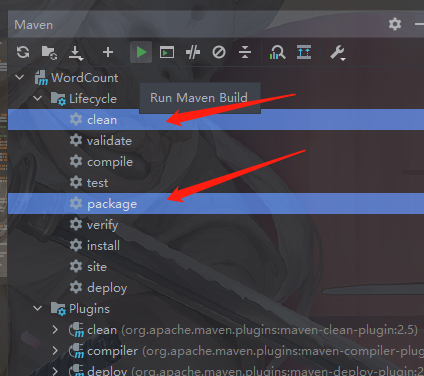
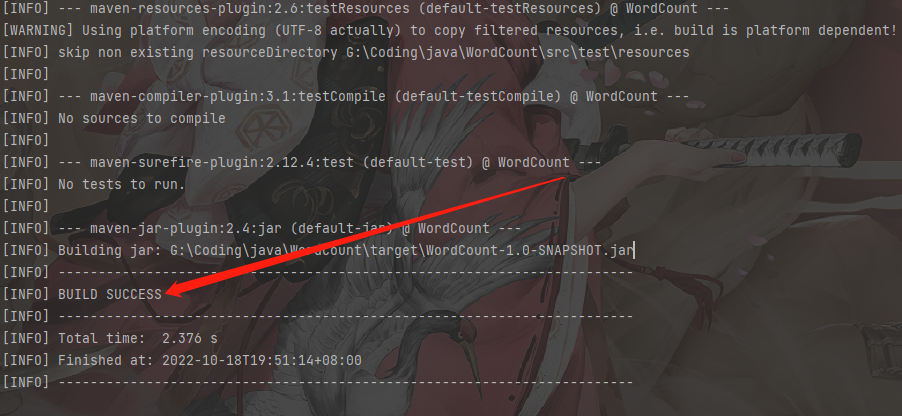
上传服务器运行
1 | # 运行jar包 |
运行
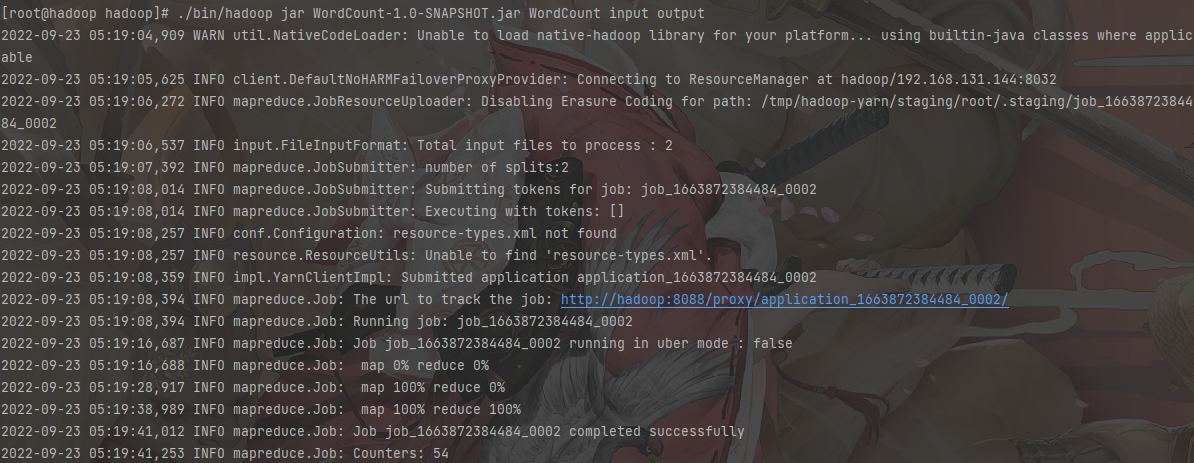
查看结果

HBase基本使用
安装
下载和安装
版本对应关系
:::tips
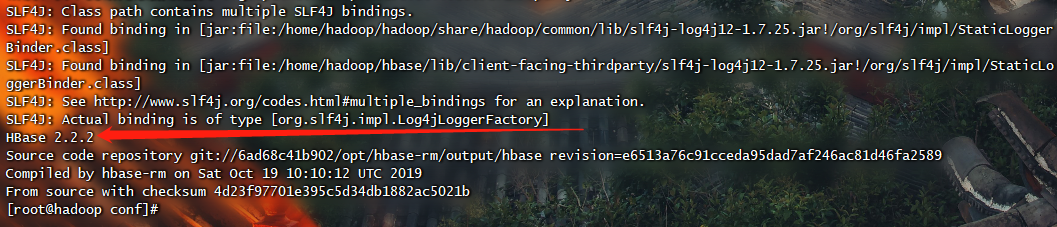
HBase版本2.2.2 (注意兼容性)
https://hbase.apache.org/book.html#hadoop
:::
下载和解压
1 | # 下载 |
配置环境变量
1 | # 编辑配置文件 |

查看HBase版本信息
1 | # 查看版本信息 |
配置
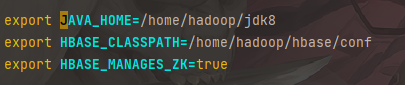
配置hbase-env.sh
1 | vim /home/hadoop/hbase/conf/hbase-env.sh |
配置hbase-site.xml
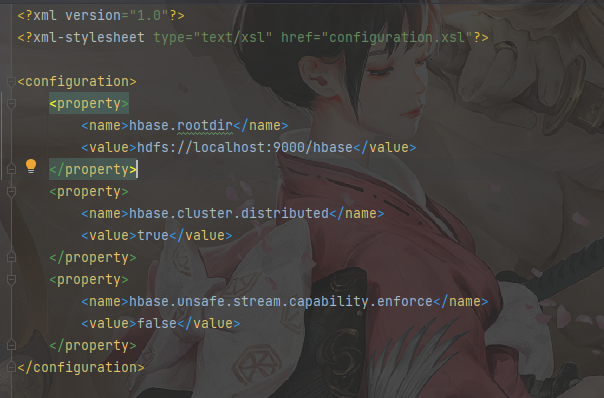
1 | vim /home/hadoop/hbase/conf/hbase-site.xml |
1 |
|
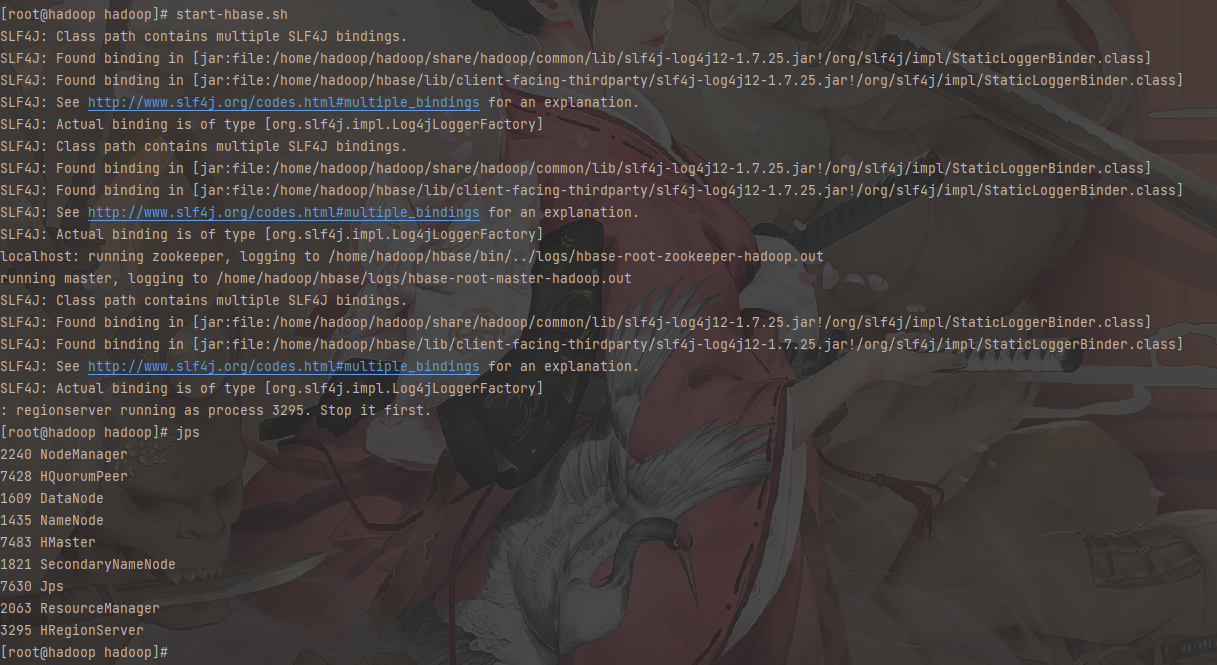
启动和停止
1 | # 首先启动Hadoop |
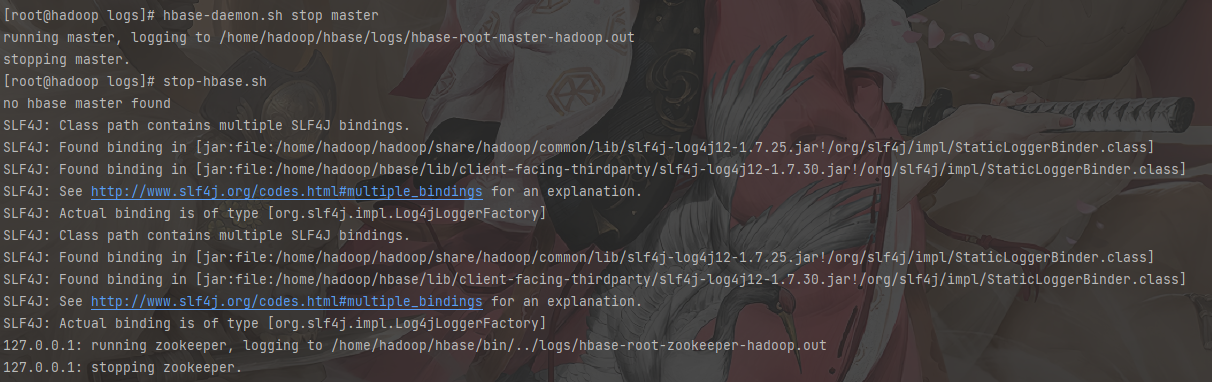
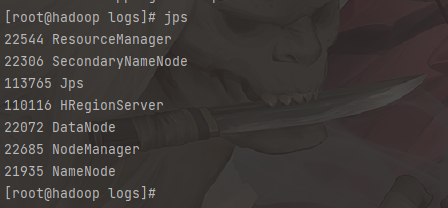
1 | # 停止HBase |
Shell命令
启动
1 | # 启动HBase Shell |
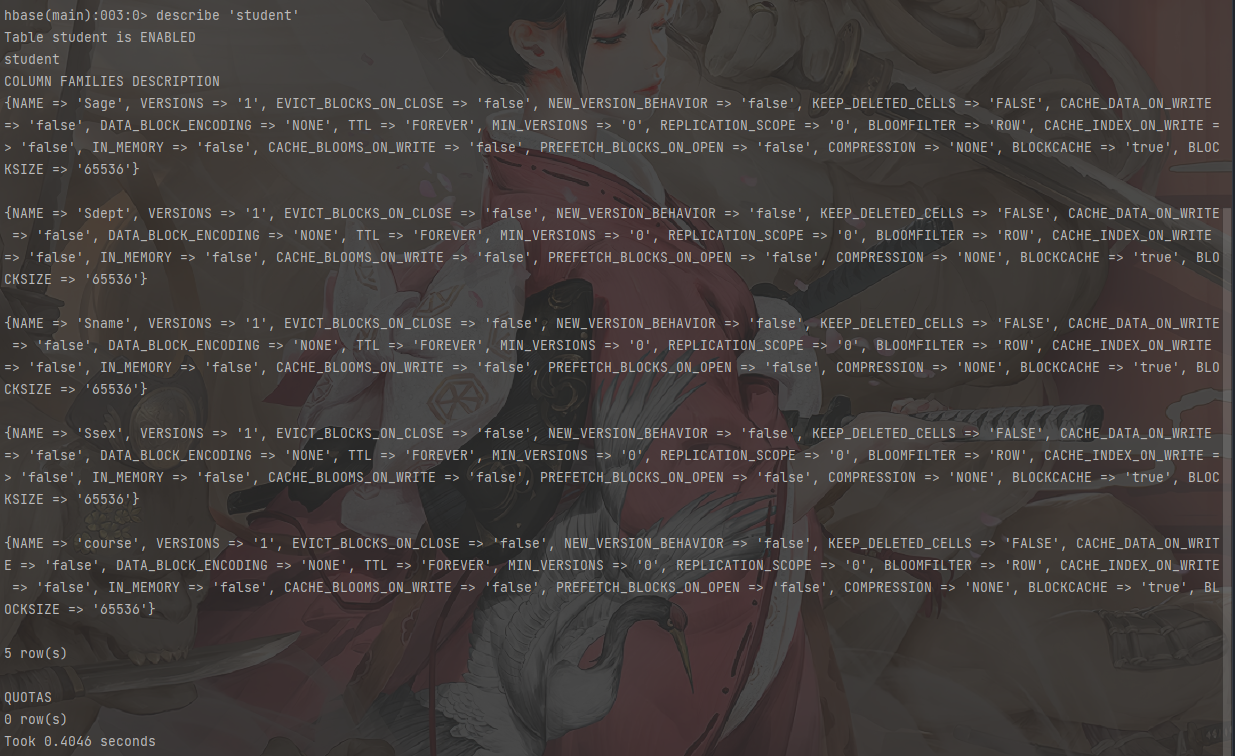
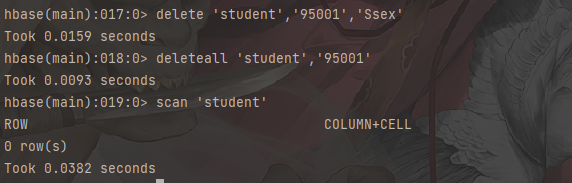
创建表
1 | # 创建表 |

删除表
1 | # 删除表 让表不可用 |
插入数据
1 | # 插入数据 |
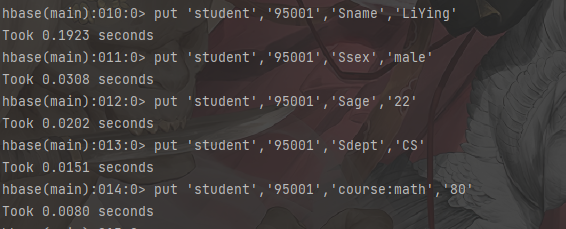
查看数据
1 | # 查看数据 查看表的某一个单元格数据 |
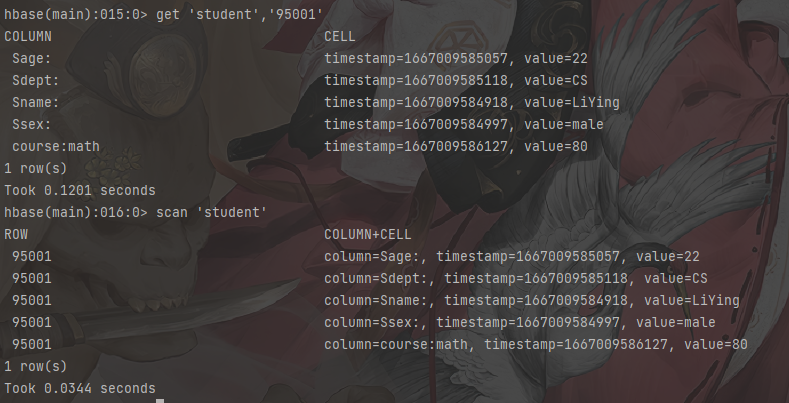
删除数据
1 | # 删除数据 删除一列数据 |
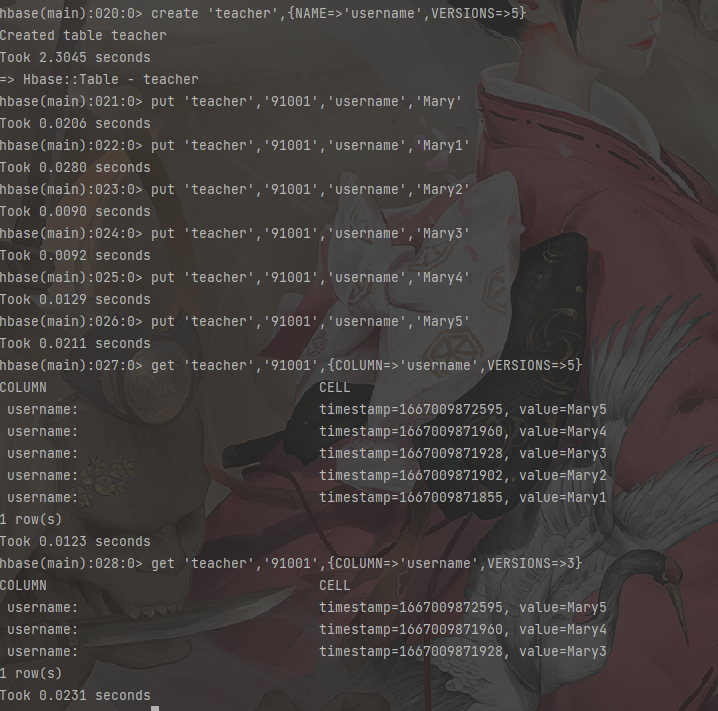
查询历史数据
1 | # 创建teacher表,指定保存的版本数(假设指定为5) |
退出
1 | exit |

Idae编程
代码连接 https://github.com/pepsi-wyl/Hbase_API
Windows添加映射
1 | # C:\Windows\System32\drivers\etc\hosts |
创建Maven并且添加依赖
1 | <dependencies> |
依赖版本要与HBase版本对应
编写代码
1 | package utils; |
Zookeeper技术
安装
单机安装
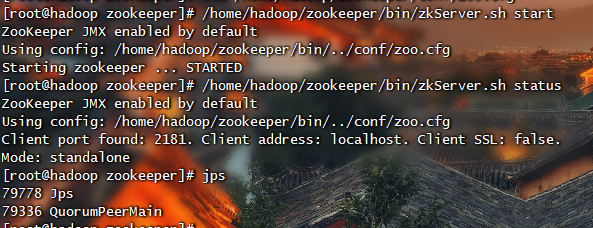
这种配置方式下没有Zookeeper副本,所以如果Zookeeper服务器出现故障,Zookeeper服务将会停止。这种应用模式主要用在测试或demo的情况下,在生产环境下一般不会采用。
1 | # 切换路径 |
1 | # 创建路径 |
1 | # 修改配置文件 |
1 | # 启动zookeeper服务 |
伪分布式安装
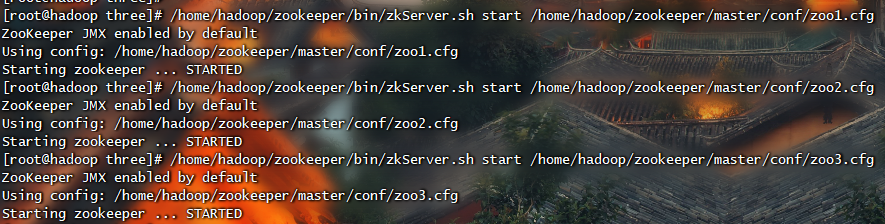
伪集群模式就是在单机模拟集群的Zookeeper服务。在Zookeeper的参数配置中,clientPort参数用来配置客户端连接Zookeeper的端口。伪分布式是使用每个配置文档模拟一台机器,也就是说,需要在单台机器上运行多个Zookeeper实例。但是必须要保证各个配置文档的clientPort不冲突即可。
1 | # 创建集群目录 |
1 | vim /home/hadoop/zookeeper/master/conf/zoo1.cfg |
1 | # myid文件缺失 https://blog.csdn.net/a_bang/article/details/72825929 |
1 | # 启动 |
1 | /home/hadoop/zookeeper/bin/zkServer.sh start-foreground /home/hadoop/zookeeper/master/conf/zoo1.cfg |
分布式安装(选作)
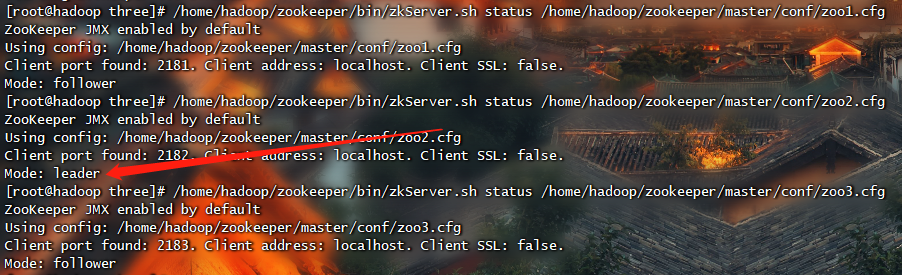
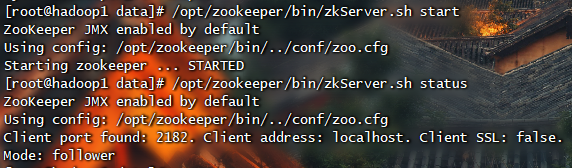
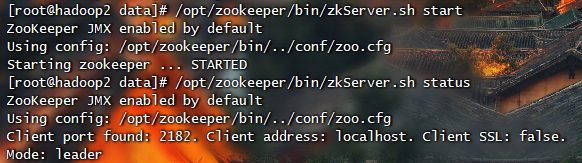
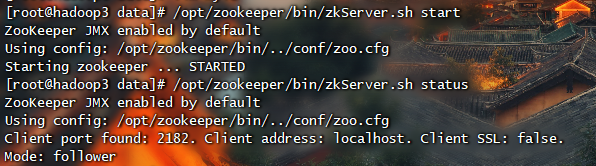
在这种模式下可以获得可靠的Zookeeper服务,只要集群中的大多数Zookeeper服务启动了,那么总的Zookeeper服务将是可用的。分布式模式下的配置与伪分布式最大的不同是Zookeeper实例分布在多台机器上。
1 | # 切换路径 |
操作
0.启动Cli
1 | # 启动Cli |
1.创建Znodes
1 | # 创建节点 |

2.获取数据
1 | # 获取数据 |


3.Watch(监视)
1 | # Watch(监视) |

4.设置数据
1 | # 设置/更改数据 |

5.创建znode子节点
1 | # 创建znode子节点 |

6.列出znode的子节点
1 | # 列出znode的子节点 |

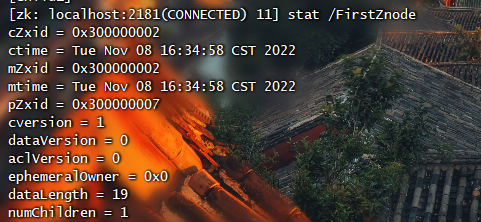
7.检查状态
1 | # 检查状态 |
8. 删除Znode
1 | # 删除Znode |

数据仓库Hive
安装
安装Mysql
本次使用Docker安装Mysql docker详解为https://www.yuque.com/pepsiwyl/blog/ghlc1t
直接安装可以参考 https://www.yuque.com/pepsiwyl/blog/zalhzm
安装Docker
1 | # 安装命令 |
启动Mysql容器
1 | # 安装mysql 账号root 密码root |
1 | # 查看mysql是否启动成功 |

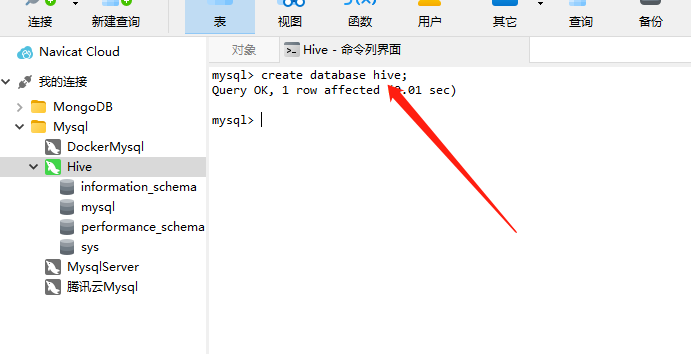
创建hive库
安装Hive
安装
1 | # 切换路径 |

添加jar包
1 | # 切换路径 |
配置Hive
1 | # 切换路径 |
1 |
|
执行初始化命令
1 | schematool -dbType mysql -initSchema |


BUG
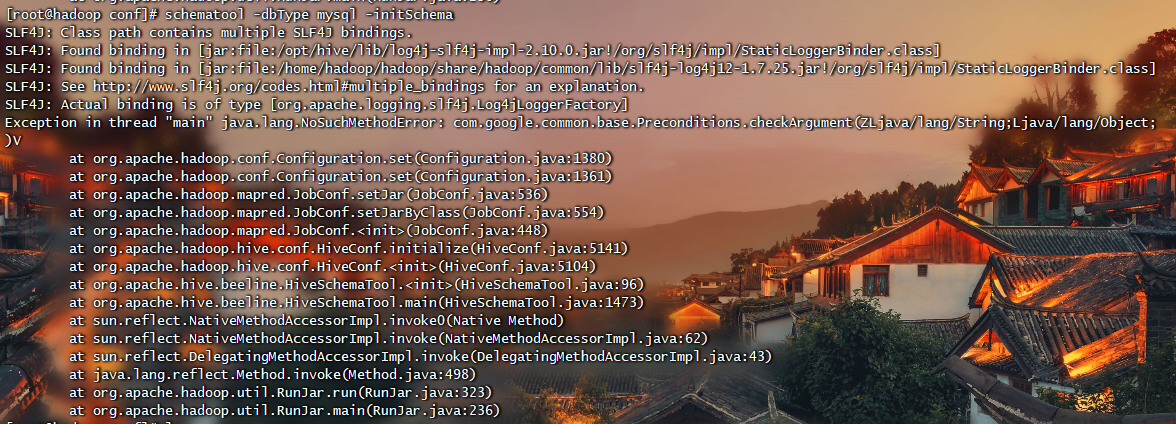
解决方法 https://www.cnblogs.com/syq816/p/12632028.html
启动
1 | # 启动之前需要先启动Hadoop 脚本: start-all.sh |
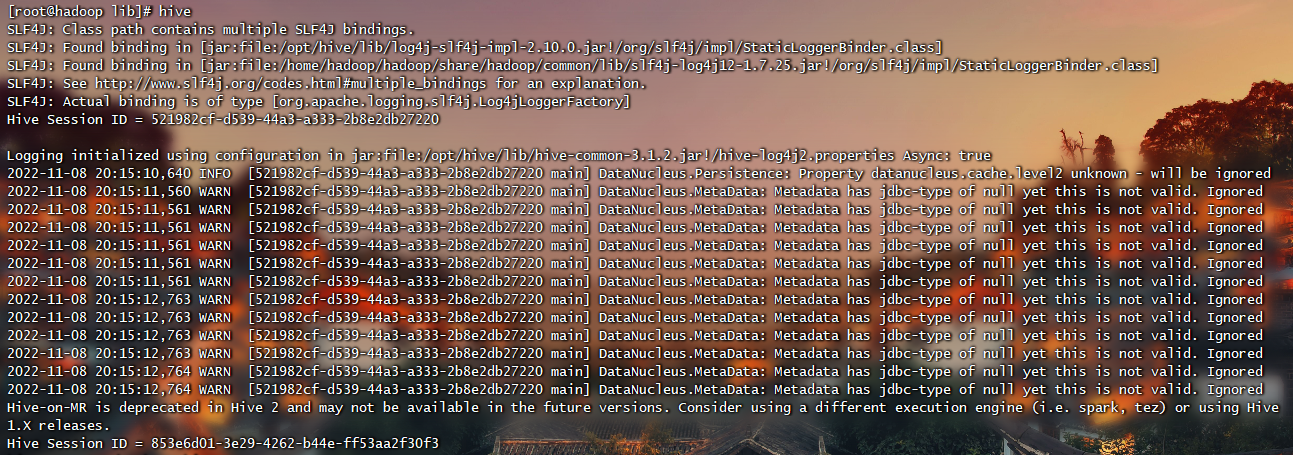
基本操作
创建数据库、表、视图
1 | # 创建数据库hive |
删除数据库、表、视图
1 | # 删除数据库 |
修改数据库、表、视图
1 | # 修改数据库 |
查看数据库、表、视图
1 | # 查看数据库 |
描述数据库、表、视图
1 | # 描述数据库 |
向表中装载数据
1 | # 把目录'/usr/local/data'下的数据文件中的数据装载进usr表并覆盖原有数据 |
向表中插入数据或从表中导出数据
1 | # 向表usr1中插入来自usr表的数据并覆盖原有数据 |
应用举例
1 | # 创建处理的HDFS路径 |
1 | # 启动Hive |
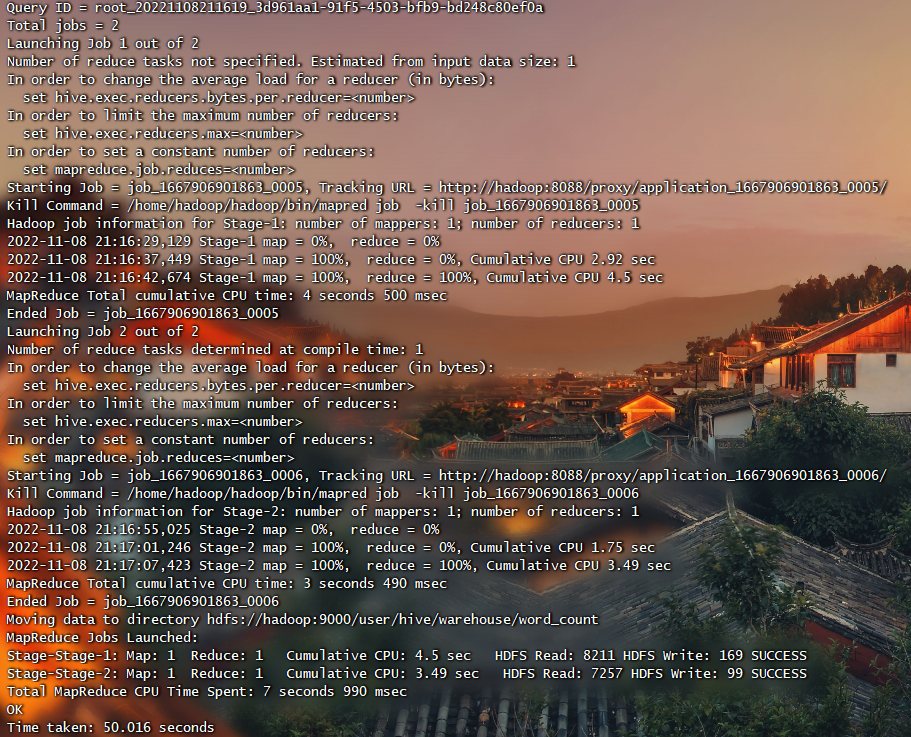
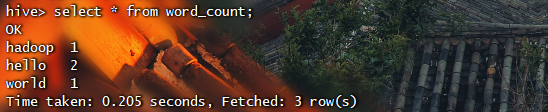
Pig技术
安装Pig
1 | # 切换目录 |
1 | # 检测pig版本 |

1 | # 检测pig是否安装成功 |
1 | # 本地模式 |
1 | # MapReduce模式 |
实验操作
创建文件并上传HDFS
1 | # 切换路径 |
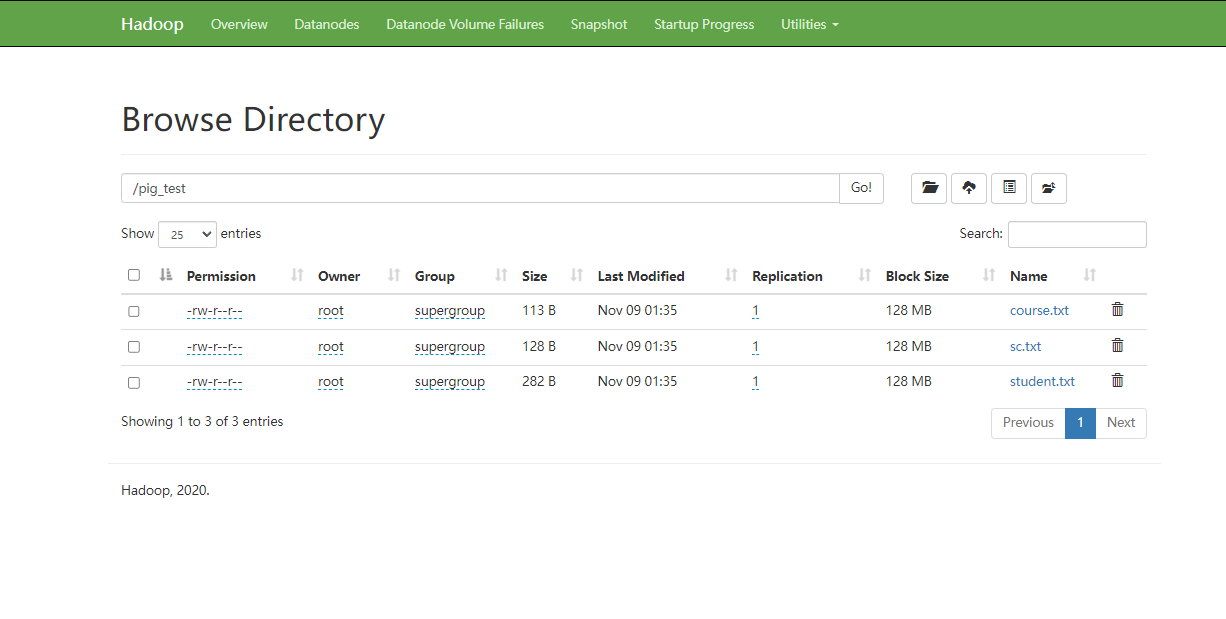
实验操作
1 | ->pig |
1 | 在hadoop集群上运行pig报如下错误:报错INFO org.apache.hadoop.ipc.Client - Retrying connect to server: 0.0.0.0/0.0.0.0:10020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS) |



Sqoop技术
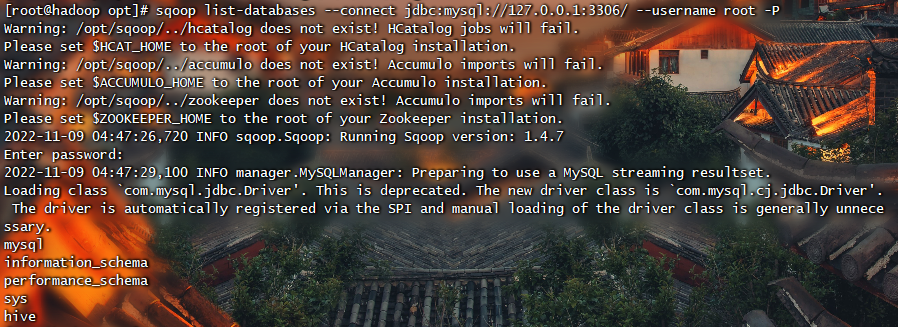
安装Sqoop
1 | # 切换目录 |
1 | # 重写命名配置文件 |
1 | # 拷贝mysql驱动 |
1 | # 测试连接数据库 |
1 | 解决BUG报错 Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/commons/lang/StringUtils |
实验操作
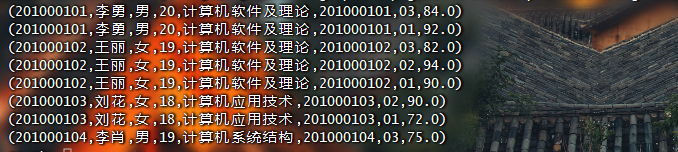
创建数据文件
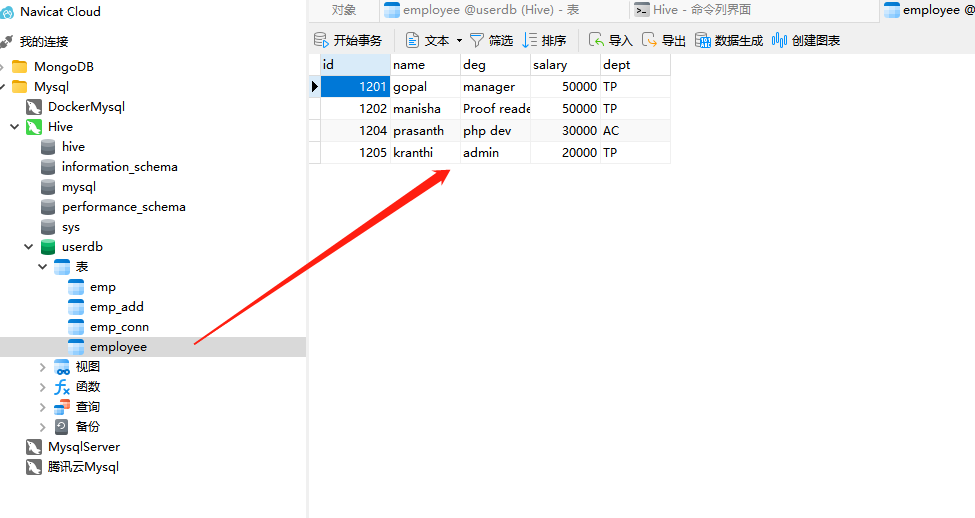
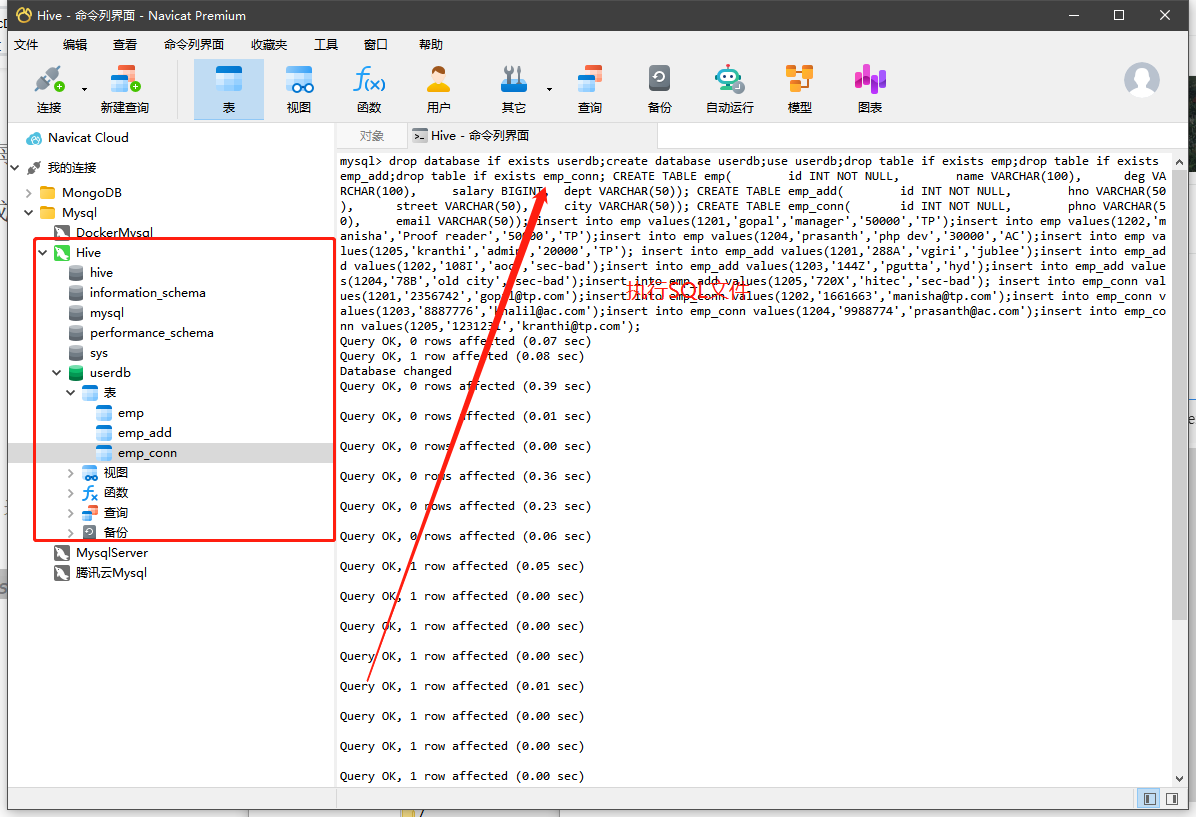
1 | drop database if exists userdb; |
Sqoop的数据导入
导入HDFS中
1 | # 导入 |

导入HIVE中
1 | # 导入HIVE的时,默认目录中不能有当前表 |
1 | // ERROR tool.ImportTool: Import failed: java.io.IOException: java.lang.ClassNotFoundException: |
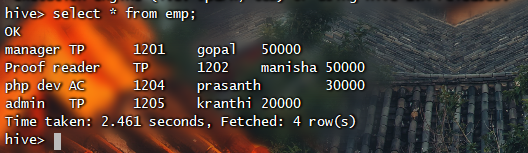
1 | ->hive |
导入表数据子集
1 | # 导入 |

Sqoop的数据导出
1 | use userdb; |
1 | # 导出 |